transformer 复习笔记

距离首次学习 transformer 已经过去一年,内容忘的差不多了,决定复习一下。
背景
距离首次学习 Transformer 已过去一年,最近在尝试回忆它的细节时,发现绝大部分内容已经模糊,于是决定系统地复盘一遍,并把过程记录下来,方便日后查阅。
本文重点记录对 Transformer 的理解与思考。代码实现主要参考 动手学深度学习,部分理论解释参考 The Annotated Transformer。
整体框架

注意力机制
注意力函数
常见的注意力函数有两种:加性注意力(additive attention)与缩放点积注意力(scaled dot-product attention)。
缩放点积注意力相比朴素的点积注意力,多了一个缩放因子 。加性注意力则通过一个带单隐藏层的前馈网络来计算兼容性分数。两者在理论复杂度上接近,但点积注意力可以直接复用高度优化的矩阵乘法实现,因此在实际中更快、也更省显存。
为了贴近实际工程的批处理方式,下面以 minibatch 的形式描述:给定 个查询和 个键-值对,查询与键的维度均为 ,值的维度为 。
查询 、键 与值 的缩放点积注意力定义为:
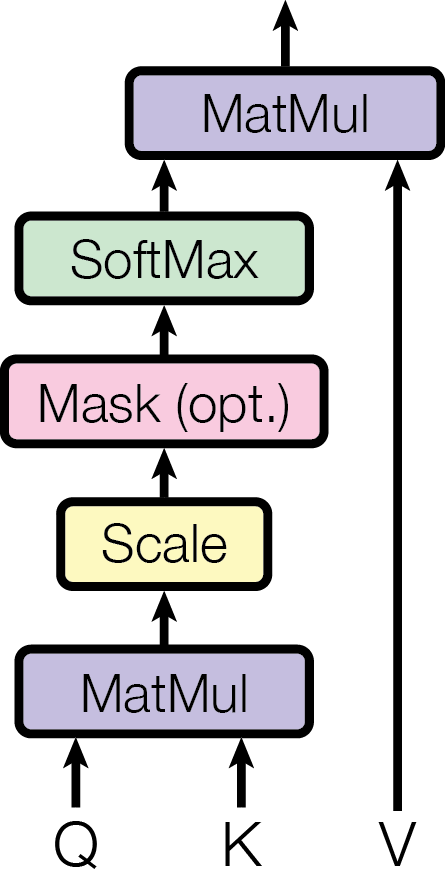
具体过程是:先用查询与所有键做点积,再除以 进行缩放,然后通过 softmax 得到值上的权重分布,最后对值做加权求和。
那么,为什么需要这个缩放因子呢?对较小的 ,加性注意力与点积注意力表现接近;但当 较大时,加性注意力反而更优。原因在于:当维度很高时,点积的数值会被放大,导致 softmax 的输出几乎集中在一个位置上,梯度也随之消失。可以做一个简化的方差分析:假设查询 与键 的每个分量都是均值 、方差 的独立随机变量,则它们的点积 的均值为 、方差为 。为了把方差稳定回 ,就需要乘上 这个缩放因子。
由于训练与推理时并非所有位置都应进入注意力汇聚(例如 padding 位置、解码器的未来位置),我们先实现一个 masked_softmax 函数,确保只有有效位置参与计算:
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
下面实现缩放点积注意力。
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
代码中的 **kwargs 表示接受任意关键字参数,是为了符合 PyTorch nn.Module 的继承约定。
多头注意力
多头注意力(Multi-Head Attention, MHA)允许模型在不同位置上同时关注来自不同表示子空间的信息。如果只用单一注意力头,加权平均的过程会把这些不同的关注模式平均掉,模型的表达力也会随之下降。

其中 ,投影参数是矩阵 , , 和 .
为了让多个头能够并行计算,我们定义两个变换函数 transpose_qkv 与 transpose_output,前者将 (batch, seq_len, num_hiddens) 重排为 (batch * num_heads, seq_len, num_hiddens / num_heads),后者负责把结果还原回原始形状。
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数, num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数, num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数, num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
位置编码
RNN 是按时间步逐个处理 token 的,天然带有顺序信息;而注意力机制为了支持并行计算放弃了顺序处理,因而失去了位置信息。为了让模型仍能感知到 token 在序列中的位置,我们需要把"位置"显式地注入到输入表示中——这就是位置编码(Positional Encoding)。位置编码与词嵌入的维度相同,均为 ,因此可以直接相加。它既可以通过参数学习得到,也可以用固定的公式直接计算。
这里我们使用基于正弦和余弦函数的固定位置编码。
设输入表示 包含一段长度为 的序列、每个 token 用 维向量表示。位置编码使用相同形状的矩阵 ,最终输出为 。其中第 行、第 与 列上的元素分别为:
其中 表示位置, 表示维度索引。也就是说,位置编码的每一维都对应一条不同频率的正弦/余弦曲线,波长从 到 按几何级数增长。选择这一形式的直觉在于:对于任意固定偏移 , 都可以表示为 的线性变换,从而让模型更容易学到"相对位置"这种关系。
class PositionalEncoding(nn.Block):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = np.zeros((1, max_len, num_hiddens))
X = np.arange(max_len).reshape(-1, 1) / np.power(
10000, np.arange(0, num_hiddens, 2) / num_hiddens)
self.P[:, :, 0::2] = np.sin(X)
self.P[:, :, 1::2] = np.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].as_in_ctx(X.ctx)
return self.dropout(X)
前馈神经网络
除了注意力子层,编码器与解码器的每一层都包含一个 position-wise 的全连接前馈网络(FFN):它对序列中每个位置独立、且共享权重地施加同一组变换,包含两个线性层与中间的 ReLU 激活:
直观上,注意力层负责"在序列内交换信息",而 FFN 负责"对每个位置做非线性变换",二者交替堆叠,使模型既能整合上下文又能拟合复杂的特征映射。
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
残差连接和层规范化
每个子层(自注意力或 FFN)外面都包了一层残差连接(residual connection)和层归一化(LayerNorm)。残差连接缓解了深层网络的梯度消失问题,让信息和梯度能够沿"恒等通路"穿透多层;而 LayerNorm 沿特征维度做归一化,相比 BatchNorm 不依赖 batch 大小,更适合变长序列的场景。
在原始论文(Post-LN)中,每个子层的输出形式为 。我们在子层输出处先应用 dropout,再加回输入并归一化。注:现代实现中更常用 Pre-LN(即 ),训练更稳定,对 warmup 也不那么敏感。
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
编码器-解码器架构
主流的神经序列转换模型大多采用编码器-解码器结构。编码器把输入符号序列 映射成连续表示 ;解码器再以 为条件,自回归地一步步生成输出序列 ——也就是说,每生成一个新词,都会把之前已经生成的所有词作为额外输入。
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
transformer 编码器
代码实现如下:
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
class TransformerEncoder(Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
transformer 解码器
代码如下:
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
class TransformerDecoder(AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
训练
训练时同样需要屏蔽 padding 等无效位置,避免它们污染损失值:
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
梯度裁剪函数:
def grad_clipping(net, theta):
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
在训练时,会把特殊的开始符 <bos> 与原始输出序列(去掉结束符 <eos>)拼接,作为解码器的输入——这种做法称为 强制教学(teacher forcing):直接将真实标签喂给解码器,避免训练早期因预测漂移导致的误差累积;与之相对的另一种选择,是让上一时间步预测出的 token 作为下一时间步的输入。
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
进行数据集的数据处理
def read_data_nmt():
"""载入“英语-法语”数据集
Defined in :numref:`sec_machine_translation`"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
def preprocess_nmt(text):
"""预处理“英语-法语”数据集
Defined in :numref:`sec_machine_translation`"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集
Defined in :numref:`sec_machine_translation`"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表
Defined in :numref:`subsec_mt_data_loading`"""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
完成数据处理后,按照 Transformer 架构搭建编码器-解码器模型并启动训练:
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, torch.device('cuda:0') if torch.cuda.device_count() >= 1 else torch.device('cpu')
ffn_num_hiddens, num_heads = 64, 4
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
decoder = TransformerDecoder(
len(tgt_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
net = EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)